
Default to Aggregation
How self-learning AI encodes the extremes of the environment it watches
This is Article 3 of 5-part series exploring why AI, social media, and strategic systems tend to amplify extremes and shape what we perceive.
Part 1 showed that AI image models amplify visual intensity — they inherit the emphases of their training data and produce outputs skewed toward drama and spectacle. Part 2 showed that social media algorithms reward friction — they systematically surface anger over agreement, and heat over signal. Part 3 asks the next question.
What happens when a system trained to recognise patterns learns from an environment already optimised for distortion? It doesn’t have morals. It doesn’t have context. It learns patterns. And the patterns it sees, overwhelmingly, are heat.

The mechanism: what self-learning actually means
Modern AI systems learn by observing statistical patterns in data and adjusting internal weights to better predict or generate those patterns. They do not evaluate whether the patterns are good, representative, or true. They encode what is statistically dominant.
Modern AI systems increasingly incorporate data that has already been shaped by other algorithms — and, in some cases, by earlier generations of AI itself. When the data a model trains on has been filtered by an environment that rewards friction over calm and heat over signal, the model does not learn human behaviour. It learns platform-skewed human behaviour. It learns what appears most often. The model learns the emphasis. Not the reality.
Two mechanisms, not one
The argument here rests on two related but distinct dynamics.
The first is distributional skew in the source data. Before any AI is trained, the data it trains on has already been shaped. Social platforms have selected for friction. News aggregators have selected for engagement. The starting distribution, the raw material the model learns from, reflects the accumulated selection pressure of every upstream system that decided what was worth surfacing and retaining.
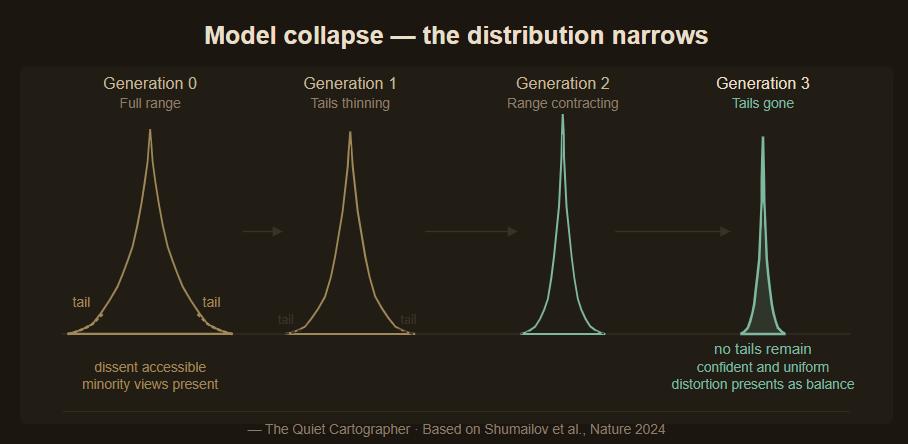
The second is recursive narrowing — what researchers call model collapse. When AI models train on data that includes outputs from previous AI models, the distribution narrows. Each generation concentrates further around what was already dominant. The tails disappear. The range contracts.
Both mechanisms compound in the same direction. The first ensures the starting distribution is already skewed. The second ensures each subsequent generation moves further from the original range. Together, they describe compounding distortion, systematic narrowing with each iteration.
Empirical anchor — Shumailov et al., Nature (2024)
In a paper published in Nature in 2024, researchers at Oxford, Cambridge, Imperial College London, and the University of Toronto demonstrated formally that training generative AI models recursively on their own output causes irreversible defects. The tails of the original content distribution disappear. Early model collapse is hard to notice — overall performance may appear stable even as the model loses fidelity on minority data. Late model collapse is unmistakable: the model confuses concepts, loses variance, and produces outputs that are simultaneously confident and narrow. The researchers described this as “the curse of recursion.” The next generation of frontier models will increasingly train on data that includes AI-generated content. The curse is not a future risk. It is already in the pipeline. The paper establishes one half of the mechanism: distributions narrow under recursive training. It does not establish the other: that platform-skewed human data produces the same effect. That comes from Part 2. The combination is the argument.
The photocopier analogy
Think of a photocopier copying its own output. The first copy looks clean. By the tenth generation, the original has been systematically distorted: dark areas darker, detail in the margins gone, the centre over-saturated.
The degradation is not random. It follows the direction of whatever the original compression favoured. If the original image had high contrast at the centre and soft detail at the edges, each successive copy will have more contrast and less detail, amplifying what was dominant, eroding what was marginal.
This is directional distortion, not simple decay. When the original image was itself the product of selection — already the high-contrast, friction-maximising version of human communication — the direction of distortion was already set. Each generation moves further from range, and closer to the spike.
The agency question
It would be easy to read this as structural inevitability — a system that was always going to produce this outcome regardless of choices made along the way. That reading is incomplete.
The structure is not accidental. It reflects objectives chosen at each layer — engagement, efficiency, scale — each rational in isolation, compounding in aggregate. Platform designers chose metrics that reward friction. Data engineers chose to scrape at scale without correcting for distributional skew. Model trainers chose evaluation frameworks that measure performance without measuring range.
Measurement is not neutral. It determines what survives.
Systems amplify what they measure. The question that follows is always: who decided what to measure, and why?
An illustrative case: platforms that close the loop
The most structurally significant instances of this dynamic emerge where AI models are trained on data from the very platform they are deployed on — creating a closed loop between what the platform rewards, what gets trained on, and what the AI produces.
Grok, developed by xAI and integrated into X, is one documented example. X uses public posts, engagement metadata, and user interactions to train and fine-tune the model. The training data has been pre-selected by the same algorithmic environment mapped in Part 2 — a platform where sustained conflict scores orders of magnitude higher than a like. xAI applies filtering, moderation, and fine-tuning processes that modify the raw signal. The structural question is how completely those downstream interventions compensate for upstream distributional skew in the source.
This is not a claim about Grok specifically. It is a structural observation about any system where training data is drawn from an engagement-optimised environment and the model is deployed back into that same environment. The loop is the issue, not the product.
The invisibility problem
Model collapse has a defining property that makes it dangerous: it is hard to notice from inside the system. In the early stages, performance metrics may appear to improve. The model becomes more confident, more consistent, more fluent.
Performance improves. Range disappears.
Standard evaluation frameworks measure accuracy, coherence, and task completion. They do not measure the diversity of the distribution the model draws from. A model that has lost its tails can perform very well on benchmarks while having systematically eliminated minority viewpoints, unusual arguments, and careful distinctions.
What looks like improvement is partly narrowing. The model becomes very good at the centre of what it learned — the centre of what the platform rewarded — while losing reach at the edges. And the edges are where the interesting things live: the dissenting analysis, the careful qualification, the argument that runs against the dominant framing.
An AI that cannot reach its edges is not less functional. It is more uniform. Uniformity in an information environment is not neutral. It shapes what feels like consensus, what feels like the range of reasonable opinion, and what feels like the boundary of acceptable thought.
Uniformity in an information environment is not neutral. It shapes what feels like consensus, and what feels like the boundary of reasonable thought.
The same pattern, three layers deep
In AI image generation, the system amplifies visual intensity because dramatic images are statistically over-represented in training data. The model learns the emphasis, not the distribution.
In social media algorithms, the system amplifies friction because engagement metrics reward replies and conflict over agreement. The platform learns what keeps people typing, not what is true or valuable.
In self-learning AI, the system aggregates and encodes the skew produced by the layers beneath it. The model trained on platform data does not learn from human communication. It learns from the version that survived the platform’s filter — and encodes that survival as the signal worth learning.
Each layer adds a compounding effect. Each layer is individually defensible. Each layer makes the next one’s skew harder to correct, because the skew has been structurally encoded rather than merely observed.
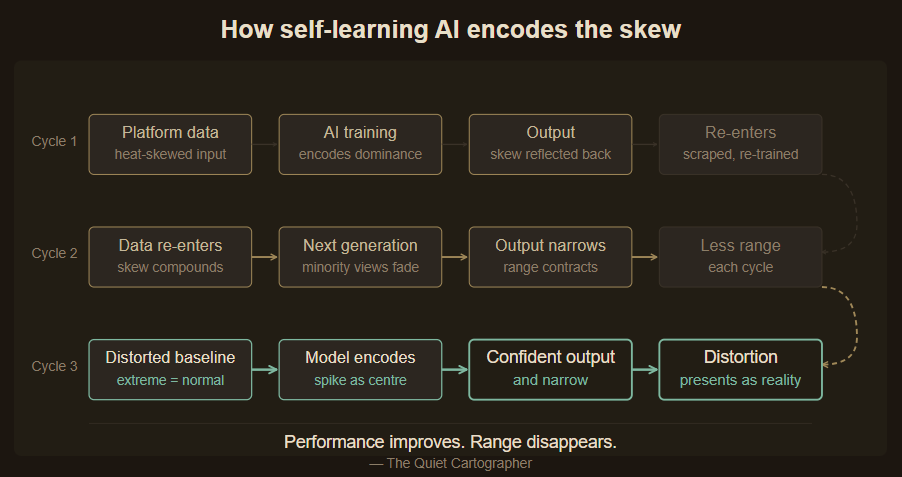
By the time the system speaks, the distortion is no longer visible as distortion. It presents as reality.
This is what default to aggregation means: the system does not intentionally narrow. It aggregates what it is given. And what it is given has already been shaped by every upstream system that selected and rewarded certain kinds of expression over others.
The AI is not the origin of the problem. It is the stage at which three layers of structural amplification become encoded into something that speaks, with the appearance of intelligence, balance, and authority.
At that point, the question is no longer what the system learned. It is what it has made difficult to think.
Next in the series
Part 4 — Default to Defence: Strategic Priorities in AI. The amplification traced here runs through culture, platform design, and self-learning systems. But there is a fourth layer that rarely enters public discussion: the strategic priorities of the governments and defence institutions that shaped AI development from its earliest stages. What happens when the training objectives include not just engagement or accuracy, but threat modelling, adversarial robustness, and strategic advantage? Next, we follow the logic to its most upstream point — into the institutions that decided, long before the public conversation began, what they wanted AI to amplify.
Follow on X: The Quiet Cartographer